特点:
- 原地排序(只需要一个很小的辅助栈);
- 将长度为 N 的数组排序所需的时间和 NlgN 成正比。
快速排序是一种分治的排序算法。 它的工作原理是将一个数组分成两部分,通过切分实现某一部分总小于另一数组,然后分别独立排序。
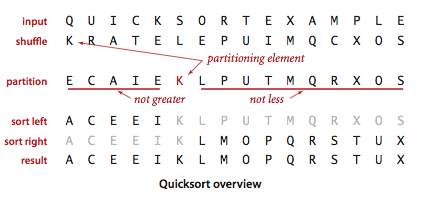
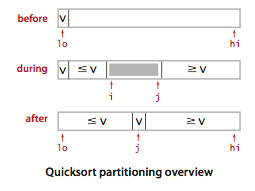
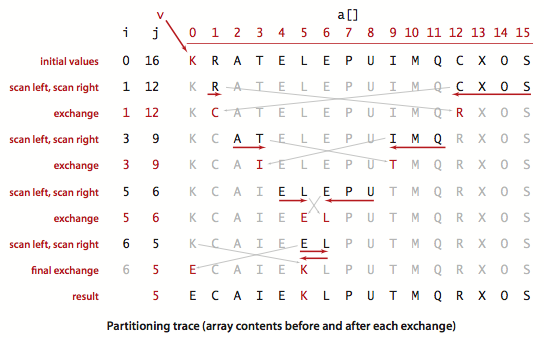
切分:一般策略是先随意地选取 a[lo] 作为切分元素,即那个会被排定的元素,然后我们从数组的左端开始向右扫描直到找到一个大于等于它的元素,再从数组的右端开始向左扫描直到找到一个小于等于它的元素。这两个元素显然是没有排定的,因此我们交换它们的位置。
如此继续,我们就可以保证左指针 i 的左侧元素都不大于切分元素,右指针 j 的右侧元素都不小于切分元素。当两个指针相遇时,我们只需要将切分元素 a[lo] 和左子数组最右侧的元素(a[j])交换然后返回 j 即可。
private static int partition(Comparable[] a, int lo, int hi) {
int i = lo;
int j = hi + 1; // 左右扫描指针
// 切分元素
Comparable v = a[lo];
while (true) {
// find item on lo to swap
while (less(a[++i], v)) {
if (i == hi) break;
}
// find item on hi to swap
while (less(v, a[--j])) {
if (j == lo) break; // redundant since a[lo] acts as sentinel
}
// check if pointers cross
if (i >= j) break;
exch(a, i, j);
}
// put partitioning item v at a[j]
exch(a, lo, j);
// now, a[lo .. j-1] <= a[j] <= a[j+1 .. hi]
return j;
}这段代码按照 a[lo] 的值 v 进行切分。当指针 i 和 j 相遇时主循环退出。在循环中,a[i]小于 v 时我们增大 i,a[j] 大于 v 时我们减小 j,然后交换 a[i] 和 a[j] 来保证 i 左侧的元素都不大于 v,j 右侧的元素都不小于 v。当指针相遇时交换 a[lo] 和 a[j],切分结束(这样切分值就留在 a[j] 中)。
public class Quick {
// This class should not be instantiated.
private Quick() { }
public static void sort(Comparable[] a) {
StdRandom.shuffle(a); // 消除对输入的依赖
sort(a, 0, a.length - 1);
assert isSorted(a);
}
// quicksort the subarray from a[lo] to a[hi]
private static void sort(Comparable[] a, int lo, int hi) {
if (hi <= lo) return;
int j = partition(a, lo, hi); // 切分
sort(a, lo, j-1); // 左半部分排序
sort(a, j+1, hi); // 右半部分排序
}
}递归的将字数组 a[lo..hi] 排序,先用 partition() 方法将 a[j] 放到一个合适的位置,然后再用递归将其他位置的元素排序。
快速排序的两个速度优势:
- 切分方法的内循环会用一个递增的索引将数组元素和一个定值比较,而归并排序、希尔排序等还在内循环中移动数据;
- 比较次数少。
将长度为 N 的无重复数组排序,快速排序平均需要 ~2NlnN 次比较(以及 1/6 的交换)。